Hugging Face — это библиотека программного обеспечения с открытым исходным кодом и сообщество, специализирующееся в технологиях обработки естественного языка (Natural Language Processing, NLP) и не только.
Предоставляет широкий спектр инструментов и моделей машинного обучения для различных задач:
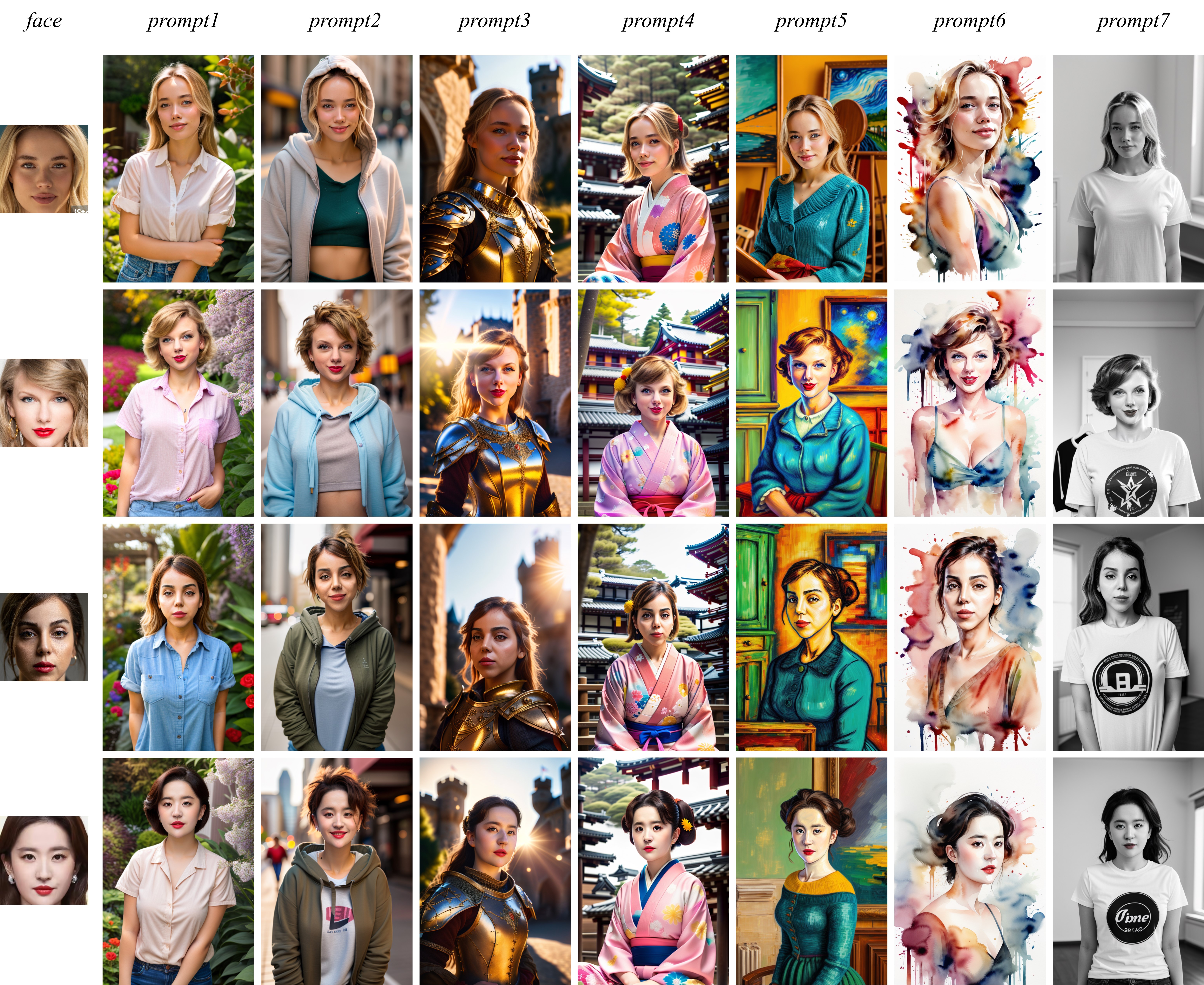
Преобразование текста в изображение
IP-Adapter-FaceID может генерировать изображения в различных стилях, при условии наличия только текстовых подсказок и лица.

Преобразование изображения в текст
Этот репозиторий содержит реализацию модели Kosmos-2 от Microsoft с использованием библиотеки transformers от HuggingFace.
Преобразование изображения в видео
Прототипная модель. Обучено с использованием https://lambdalabs.com ❤ 1xA100 (40 ГБ) 2197 видеороликов, 68388 помеченных кадров ( salesforce/blip2-opt-6.7b-coco ) шаги_обучения: 10000
Всего более 500К моделей
- Извлечение функций (Models — 6,571)
- Преобразование текста в изображение (Models — 14,176)
- Преобразование текста в видео (Models — 72)
- Визуальный ответ на вопрос (Models — 105)
- Классификация изображений (Models — 8,619)
- Обнаружение объектов (Models — 1,322)
- Классификация видео (Models — 461)
- Классификация текста (Models — 44,462)
- Вопрос — Ответ (Models — 8,940)
- Перевод (Models — 3,081)
- Текст в речь (Models — 1,699)
- Автоматическое распознавание речи (Models — 13,462)
- Классификация аудио (Models — 1,508)
- Обнаружение голосовой активности (Models — 20)
- Робототехника (Models — 16)
- Генерация текста (Models — 39,540)
И ещё масса заготовок для нейросетей под любые нужды.
С помощью Hugging Face пользователи могут получить доступ к предварительно обученным моделям, донастраивать их для конкретных задач и даже создавать свои собственные модели для решения уникальных проблем.
Более 90К баз данных для обучения нейросетей
Набор данных Википедии, содержащий очищенные статьи на всех языках. Набор данных построен на основе дампов Википедии ( https://dumps.wikimedia.org/ ) с одним подмножеством для каждого языка, каждый из которых содержит одно разделение поездов.
Набор данных охватывает 50 пространственных областей, охватывающих 916 территорий площадью 817 км². Этот набор данных обеспечивает надежную основу для совершенствования методов картографирования земного покрова.
Отличительной особенностью этого набора данных является его объем. Он может похвастаться колоссальными 420 000 учебниками . Эта обширная коллекция обеспечивает широкий охват тем и концепций, предоставляя вашим моделям всеобъемлющий и разнообразный учебный ресурс.
Более того, этот набор данных генерируется с использованием языковой модели с открытым исходным кодом, что гарантирует, что данные открыты для обработки каждым исследователем.
Spaces

Более 7000 работающих нейросетей, созданных и протестированных сообществом. Можно использовать бесплатно прямо на сайте.
Добавить комментарий